Distribuição Normal – Hidrologia Estatística
A distribuição normal assume que os dados de precipitação máxima, ou qualquer outra variável aleatória, são normalmente distribuídos.
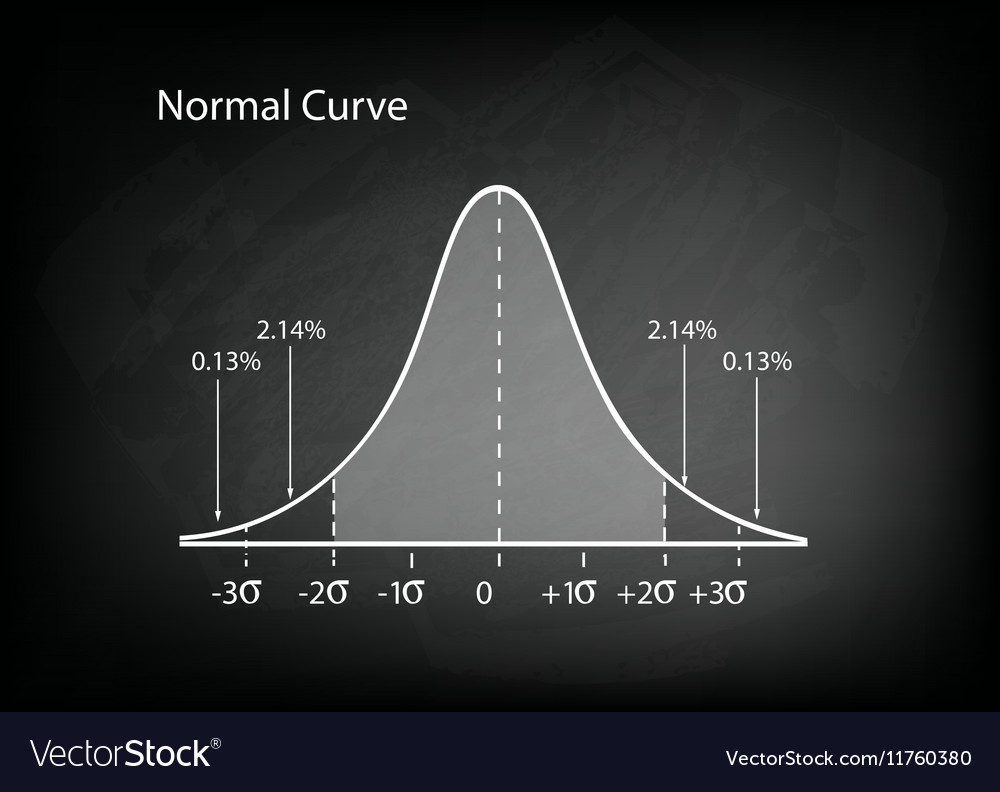
A frequência acumulada dessa distribuição é bem conhecida e tem funções próprias dentro do Excel.
Essa função é expressa por:
$$ P(x \leq x_m) = F(x,x_m) = \int_{-\infty}^{x_m}\frac{1}{\sqrt{2 \pi s}} \mathrm{e}^{-\frac{1}{2}(\frac{x – \bar{x}}{s})^2}\mathrm{dx}$$
onde $F(x,x_m)$ é a frequência acumulada de se obter valores de x menores ou iguais a um valor esperado, $\bar{x}$ é a média da amostra e $x_m$ e $s$ é o desvio padrão da amostra.
É fácil observar que a probabilidade de se ter valores maiores ou iguais a $F(x,x_m)$ é justamente $1 – F(x,x_m)$.
A equação acima, no entanto, não tem solução analítica.
Assim, métodos numéricos são utilizados para resolvê-la.
No Excel, podemos utilizar a função $\texttt{NORMDIST}$ que toma como argumentos a média, desvio padrão amostral e categoria de função (e.g. mássica ou cumulativa).
Desse modo, um valor $x_m$ é descrito pela média $\bar{x}$, pelo desvio padrão $s$ e sua frequência acumulada $F(x,x_m)$ associada ao valor $x_m$, de modo que:
$$x_m = \bar{x} + s F(x,x_m)$$
A função cumulativa de distribuição de probabilidade normal ($F(x,x_m$)) tem como entrada o valor da precipitação.
No entanto, sua função inversa retorna o valor de $x_m$, para uma dada conhecida frequência acumulada $F(x,x_m)$. No excel temos $\texttt{NORM.INV}$.
Exemplo 1) – Distribuição Normal – Hidrologia Estatística
Dada a série de precipitações $\mathbf{P} = [100,~120,~200,~150,~160,~175,~155,~170,~165,~190,~175,~200]^T$, determine o valor esperado de precipitações máximas para um tempo de retorno de 10 anos.
Esse é o mesmo exemplo resolvido no artigo sobre o método de Gumbel, disponível aqui:
Solução:
Precisamos determinar a probabilidade de excedência de uma chuva de 10 anos, baseado na série histórica.
Assim, calculando a média e o desvio padrão chegamos em 163.33 mm e 29.9 mm.
Se o tempo de retorno é TR, a probabilidade de excedência é:
$$ 1 – F(x,x_m) = \frac{1}{\mathrm{TR}}$$
O objetivo agora é encontrat $x_m$, isto é, o valor associado ao tempo de retorno $\mathrm{TR}$, de modo que:
$$ P(x \geq x_m) = 1 – F(x,x_m) = \frac{1}{\mathrm{TR}} = 1 – \int_{-\infty}^{x_m}\frac{1}{\sqrt{2 \pi s}} \mathrm{e}^{-\frac{1}{2}(\frac{x – \bar{x}}{s})^2}\mathrm{dx}$$
Resolvendo no excel, basta calcularmos $\texttt{NORM.INV}(1 – F(x,x_m), \bar{x},s)$, o que, se aplicarmos ao caso de um TR = 10 anos, fica:
$$ x_m = \texttt{NORM.INV}(1/10,163.33,29.9) = 201.7~\mathrm{mm}$$
Nesse caso um valor bem próximo ao do reportado no artigo do Método de Gumbel.
Isso não é regra e sim uma coincidência.
Finalmente, por se tratar de uma distribuição normal, podemos escrever:
$$ F(x,x_m) = \frac{x_m – \bar{x}}{s}$$
Resultando em:
$$ x_m = \bar{x } + sF(x,x_m)$$
Distribuição Log-Normal
Outra possibilidade é, ao invés de assumir que os dados seguem uma distribuição normal, assumir que o logarítmo dos dados seguem.
$$
\overbrace{\log \left(x_m\right)}^{x_m^*}=\overbrace{\log (x)}^{\bar{x}^*}+\overbrace{S_{\log (x)} F\left(\log (x), \log \left(x_m\right)\right)}^{s F\left(x, x_m\right)^*}
$$
Assim, fazemos o mesmo procedimento de ajuste pela distribuição normal, mas ao invés de usarmos a variável aleatória $x$, usamos agora a variável aleatória $x^* = \mathrm{log}(x)$.

Mestre e Doutor em Engenharia Hidráulica e Saneamento pela USP – São Carlos. Vencedor do Prêmio Tese Destaque de teses da USP (2024) e autor de diversos artigos nacionais e artigos internacionais. Pesquisador de Pós-Doutorado II na University of Arizona, Department of Hydrology and Atmospheric Sciences, USA. Engenheiro civil formado pela Universidade Estadual de Maringá. Fundou o canal Engenheiro Planilheiro em 2017 após perceber que suas planilhas poderiam dar uma contribuição real para diversos engenheiros, arquitetos e profissionais da área, contando com mais de 100 mil planilhas já baixadas e diversos clientes atendidos no Brasil e no mundo.


